Qualitätssicherung & Testing in der Softwareentwicklung
In der schillernden Welt der Softwareentwicklung können selbst die alteingesessensten Softewareprodukte im Laufe der Zeit Ineffizienzen anhäufen (und tatsächlich scheint das eher die Regel als die Ausnahme zu sein). Faktoren wie ausufernde Projektumfänge, fortwährender Featurecreep, Lieferdruck und die Binsenweisheit „wenn es funktioniert, pack's bloß nicht an“ führen oft dazu, dass Leistungsoptimierungen in den Hintergrund treten müssen. Diese Lasten entstehen üblicherweise nicht über Nacht, sondern schleichen sich langsam in den Code ein, ohne dass es jemand bemerkt. Viele Teams gewöhnen sich geradezu daran, dass „bestimmte Schritte schon immer langsam waren”, und nehmen langwierige Laufzeiten von selten ausgeführten Operationen widerstrebend hin.
In diesem Blogbeitrag begeben wir uns auf die Suche nach so einem langjährigen Leistungsproblem, setzen ein einfaches Ressourcen-Überwachungssystem auf und betrachten die (dieses Mal) einfachen Schritte, die die Leistung unserer Software deutlich verbessert haben. Dies ist der erste von zwei Teilen, die sich mit diesen Problemen in einer ausgewählten Anwendung beschäftigen.

Leistungsmängel identifizieren mit Monitoring & Profiling (© Foto mit KI generiert, Adobe Stock von Illugram)
Das Untersuchungsobjekt
Unser Corpus Delicti ist eine maßgeschneiderte Webanwendung für einen einzelnen Kunden, um elektronische Fahrzeugkomponenten zu entwickelt und zu verwalten. Jede Komponente besteht aus mehreren Steckverbindern, und jeder Steckverbinder enthält mehrere einzelne Kontakte. Damit noch nicht genug – Komponenten, Stecker und Kontakte kommen in verschiedenen Hardwareversionen, und jeder Steckverbinder und Kontakt wird versioniert. Je nach Größe und Komplexität der Komponente ergibt sich daraus manchmal ein riesiger, komplexer Abhängigkeitsbaum.
Ursprünglich war der Umfang der Anwendung schmal und zielstrebig definiert, wurde aber im Laufe der Jahre erheblich erweitert. Die Größe jeder Komponente und folglich die Komplexität des Abhängigkeitsbaums sind dabei schneller angewachsen als bei Projektstart absehbar war. Die Leistungsprobleme, mit denen wir jetzt zu tun haben, sind demnach auch nicht plötzlich aufgetreten; sie waren – wie eingangs angedeutet – ein schleichender und fortlaufender Prozess.
Unsere Protagonisten in dieser Geschichte sind drei elektronische Komponenten, “Der Hund”, “Der Esel” und “Die Hydra”.
Der Hund
Der Hund ist eine friedfertige, genügsame Komponente, die einen kleinen Abhängigkeitsbaum hat und in der Webanwendung schnell geladen wird. Glücklicherweise sind die meisten Komponenten im Arsenal des Kunden hundeartiger Natur und verursachen minimale Probleme.
Der Esel
Dazu kommen ein paar größere Komponenten mit mehreren Steckverbindern und vielleicht hundert Kontakten, jeweils mit einigen Revisionen. Der Kunde besitzt einige Komponenten dieses Kalibers, und während das Laden und Speichern von ihnen in der Webanwendung ein wenig Entschlossenheit erfordert, ist das eigentliche Bearbeiten (was den der Hauptteil der Arbeit darstellt) tatsächlich hinreichend schnell.
Die Hydra
Diese letzte Komponente bereitet uns nur Kopfschmerzen, gleichwohl es lediglich eine von ihr gibt. Selbst im Vergleich mit anderen großen Komponenten ist sie riesig. Sie ist sehr komplex, gefährlich, wenn man sie falsch anpackt, und das Laden und Speichern dieser Komponente in der Webanwendung dauert eher Minuten als Sekunden. Es wird gemunkelt, dass mehrere Ingenieure beim Bändigen dieses Biestes verschollen sind. Obwohl diese Komponente ein Außenseiter ist, ist sie unglaublich wichtig für unseren Kunden.
Über welche Performanceprobleme sprechen wir?
Ein typischer Workflow in der Anwendung besteht darin, eine Komponente zu laden, einige Anpassungen an den Steckverbinder-oder Kontaktdaten vorzunehmen und die Komponente zu speichern. Sobald eine Komponente für die Massenfertigung bereit ist, werden alle Daten darin gemäß den Unternehmensrichtlinien auf Konsistenz geprüft und anschließend eingefroren. Nach dem Einfrieren können die Daten nicht mehr geändert werden; stattdessen muss eine neue Revision der Komponente erstellt werden, indem die letzte eingefrorene Revision kopiert wird.
Fangen wir mit den bisherigen Lade- und Speicherzeiten unserer Protagonisten an, um zu sehen, womit wir es überhaupt zu tun haben:
| Komponente | Laden | Speichern | Kopieren | Regelprüfung & Einfrieren |
| Der Hund | ~ 2 Sek. | ~ 3 Sek. | ~ 3 Sek. | ~ 6 Sek. |
| Der Esel | ~ 40 Sek. | ~ 15 Sek. | ~ 15 Min. | ~ 3 Min. |
| Die Hydra | ~ 90 Sek. | > 3 h | > 4 h | > 1 h |
Schon hier wird deutlich klar, dass selbst “unproblematische” Komponenten wie Der Hund einige Sekunden für alltägliche Interaktionen benötigen. Für eine Endanwendernutzung wäre das allein schon zu langsam. Da die meisten Benutzer Elektroingenieure sind, die in diesem einen Unternehmen arbeiten und mit den zugrunde liegenden Komplexitäten innig vertraut sind, wurden einige Sekunden Wartezeit bisher als akzeptabel betrachtet. Dazu war die Anwendung in der Vergangenheit deutlich schneller, da die Vorgänger der jetzigen Komponenten kleiner und weniger komplex waren. Aber das Leben – und unerwünschte Performanceprobleme – finden immer ihren Weg.
Es ist geradezu obligatorisch, dass das Speichern der Hydra schlichtweg in weniger als drei Stunden zu schaffen sein muss. Bisher läuft es aber darauf hinaus, dass ein Ingenieur seine oder ihre über den gesamten Tag verrichtete Arbeit erst kurz vor Schichtende speichern kann - und dann sollte man besser keine erforderlichen Felder übersehen haben: Das Speichern würde dann nämlich fehlschlagen. Dies entspricht dabei sogar dem erwünschtem Verhalten, damit keine fehlerhaften Daten gespeichert werden können. Trotzdem ist es einfach frustrierend, Stunden zu warten, nur um dann einen Fehler zu sehen. Während die zu erzielenden Performanceverbesserungen also vor allem der Hydra zugute kommen sollen, machen diese langsamen Lade- und Speicherprozesse das Debuggen zu einer wahren Geduldsprobe.
Es ist ebenfalls auffällig, dass alle diese Prozesse keinem linearen Muster zu folgen scheinen, d.h. es gibt keine strikte Regel, die besagt: “wenn das Laden N Sekunden dauert, wird das Speichern 30 * N Sekunden dauern” oder vergleichbares. Die großen Komponenten brauchen länger als die kleinen, so viel ist klar. Aber es scheint eine gewisse Inkonsistenz darin zu geben, wie viel genau länger. Das bedeutet auch, dass wir nicht einfach mit den kleinsten Komponenten testen und debuggen können, weil es mehrere zugrunde liegenden Probleme geben könnte, die unterschiedlich stark auftreten.
Ursachenforschung mit Monitoring und Profiling
Im ersten Schritt geht es darum festzustellen, wo es genau hakt. Unsere Anwendung ist in Java geschrieben und verwendet Vaadin für das Frontend und eine Oracle Datenbank im Backend. An dieser Stelle verwendet man für gewöhnlich einen sogenannten Profiler – ein Programm, das einem detaillierte Informationen zum Laufzeitverhalten von Software geben kann. Zum Beispiel kann man sehen, wie lange einzelne Funktionsaufrufe gebraucht haben, welche anderen Funktionen sie aufrufen und wie viel Arbeitsspeicher wofür verwendet wird.
Oftmals bietet es sich aber an, das Problem noch makroskopischer zu betrachten: Welcher Teil des Gesamtsystems ist am langsamsten? Schließlich bestehen die meisten modernen Webanwendungen aus mehreren interagierenden Komponenten. Unsere Anwendung beispielsweise besteht aus einem kombinierten Frontend/Backend Modul, einem Webserver, einer Oracle Datenbank und einem Modul, welches die Authentifizierung im Unternehmensnetzwerk vermittelt. Mit dem Monitoring Tool Glances, fühlen wir diesen vier Modulen auf den Zahn.
Glances
Monitoring mit Glances (Screenshot © eXXcellent solutions)
Glances ist ein plattformübergreifendes Monitoring-Tool, das in Python geschrieben wurde und einen tieferen, detaillierteren Einblick in die Leistungsmessungen des Systems bietet. Es zeigt eine breite Palette an Systemmetriken, einschließlich CPU, Speicher, Festplatten-I/O, oder Netzwerktraffic, alles in Echtzeit. Wenn unsere Module in Containern laufen, können wir diese Ressourcen auch aufgeteilt pro Container betrachten. Glances unterstützt vor allem den Datenexport nach Grafana, womit sich diese Daten gut visualisieren lassen:
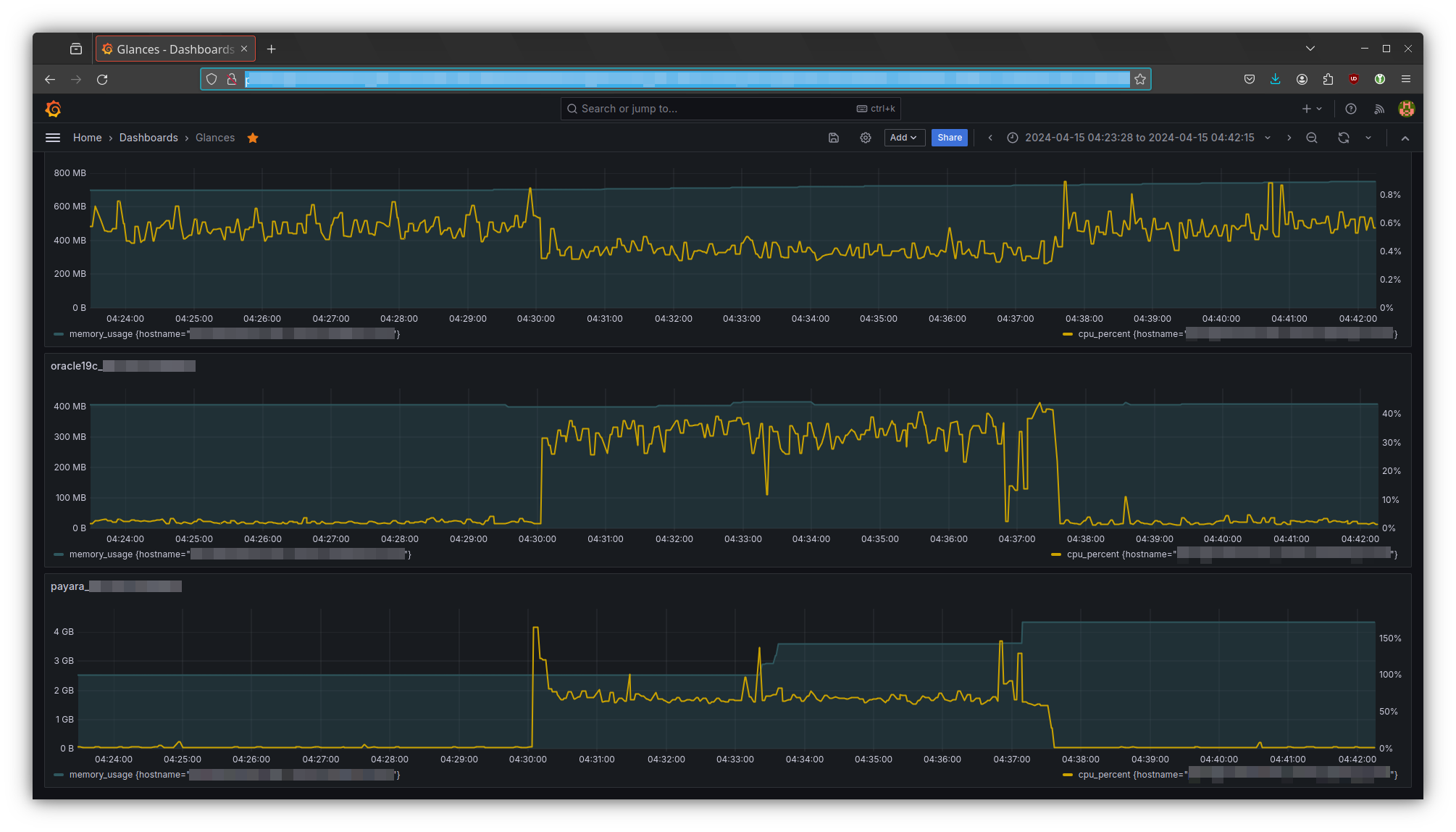
Visualisierung mit Grafana (Screenshot © eXXcellent solutions)
Im obigen Screenshot sehen wir CPU-Last und Speicherbedarf von zwei Docker-Containern auf demselben Host. In diesem Fall der Datenbank und des Frontend / Backendmoduls. Und da eins von beidem deutlich mehr Last verursacht, haben wir direkt die nächste heiße Spur gefunden: die Datenbank.
Während also insbesondere die Laufzeitmessung im Profiler hier sehr vielversprechend klingt, führt sie diesmal ins Leere – unsere Anwendung ist gar nicht der Hauptverursacher der CPU-Last. Oder zumindest nur indirekt. Es stellt sich heraus, dass der Großteil der Wartezeit durch die Datenbank verursacht wird, die anscheinend mit den Anfragen, die unsere Anwendung stellt, viel zu tun hat.
Datenbankanfragen in Frage stellen
Um der Sache auf den Grund zu gehen, schauen wir nach, welche exakten SQL-Anfragen bearbeitet werden und wie lange das jeweils dauert. Ein Vorgang in der Anwendung kann dutzende Datenbankanfragen nach sich ziehen, aber auffällig lange gebraucht haben in diesem Fall lediglich drei. Das kann mehrere Ursachen haben:
- Erfordert die Anfrage besonders viele Daten?
- Erfordert die Anfrage eine ungünstige Kombination verschiedener Daten? Also müssen beispielsweise komplizierte Einschränkungen oder Verknüpfung verschiedener Datenbanktabellen bearbeitet werden?
- Liegen die geforderten Daten in einer gut sortierten, einfach abzufragenden Struktur vor, oder müssen sie mühselig gesucht werden?
Nicht selten können diese Faktoren auch in Kombination auftreten. Deren Analyse und Behebung ist hochgradig kontextabhängig und erfordert tiefgehendes Domänenwissen und Verständnis der Funktion der Anwendung. Allgemeine Aussagen sind hier schwer zu treffen, folgende Denkanstöße können aber beim Untersuchen von Enpässen der Datenbankperformance helfen:
- Liegen die Daten in einer geeigneten Struktur vor, wenn regelmäßig umfangreiche Abfragen nach ihnen gemacht werden?
- Oder müssen aufwendige Kombinationen zur Abfragezeit berechnet werden?
- Lassen sich solche Kombinationen vereinfachen?
- Werden Daten abgefragt, die gar nicht angezeigt werden?
Diese Fragen betreffen nur die Abfragelogik, die unsere Anwendung erfordert. Optimierungen an der Datenbank selbst können auch relevant sein. Im Großen und Ganzen ließ sich die Art, wie die Daten in den Tabellen vorlagen, erheblich verbessern, sodass nicht mehr komplette Spalten durchsucht werden mussten, wenn bestimmte Daten abgefragt wurden. Stattdessen kann jetzt auf geforderte Daten zielstrebig und ohne große Umwege zugegriffen werden, was die Performance unserer Anwendung erheblich verbessert hat.
Fazit
Die Tabelle zeigt die Verbesserung der Ladezeiten sowie der Regelprüfung und des Einfrierens. Die verbleibenden Spalten "Speichern" und "Kopieren", sind auf ein anderes Leistungsproblem zurückzuführen und werden im nächsten Blogartikel erläutert.
| Komponente | Laden vorher |
Laden nachher |
Regelprüfung & Einfrieren vorher |
Regelprüfung & Einfrieren nachher |
| Der Hund | ~ 2 Sek. | ~ 1 Sek. | ~ 6 Sek. | ~ 2 Sek |
| Der Esel | ~ 40 Sek. | ~ 2 Sek. | ~ 3 Min. | ~ 18 Sek |
| Die Hydra | ~ 90 Sek. | ~ 2 Sek. | > 1 h | ~ 59 Sek |
Letztendlich handelte es sich bei dem zugrundeliegenden Problem um keine Raketenwissenschaft. Denn im Nachhinein haben sich die Optimierungen als geradezu trivial und offensichtlich erwiesen – wenn man denn weiß, worauf man achten muss!
Was uns zu einem wirklich hinterhältigen Problem führt: Computer sind schnell. Das mag jetzt erstmal nach einer seltsamen Beschwerde klingen, aber Tatsache ist einfach: Diese Probleme traten schlicht nicht auf, solange die Komponenten eher wie Der Hund waren: klein und gutartig mit wenig Abhängigkeiten. Als sich das Datenmodell langsam vergrößerte, wurden die Abfragen Stück für Stück komplexer und umfangreicher. In kleinen Versionssprüngen merkt man das nicht ohne Weiteres. Aber irgendwann überwiegen die Komplexitäten und die Anwendung wird spürbar langsamer. Und so waren unsere Computer irgendwann eben doch nicht mehr schnell genug.
Derartige Probleme gibt es überall in der Software-Welt, und es empfiehlt sich, eine Problemlösungsstrategie in der Hand zu haben, die flexibel genug ist, um auf verschiedene Probleme zu reagieren. Probleme müssen frühzeitig erkennbar sein, bevor sie merklichen Schaden anrichten. In diesem Kontext haben wir kontinuierliche Performance-Tests in unsere automatischen Software-Tests aufgenommen, sodass wir auftretende Performancedegradationen direkt bemerken und quantifizieren können. Wenn diese Tests auf Probleme hinweisen, bedienen wir uns der Monitoring-Tools, und brechen das Problem vom Großen ins Kleine herab. Wenn klar ist, welches Modul problematisch ist, betrachten wir seine gewünschte Funktion und wie diese umgesetzt ist, um schlussendlich die eine Stellschraube zu erwischen, mit der wir das Problem lösen können.
Gilde „Qualität & Test“
Unsere „Profiler“ bei eXXcellent solutions sind die Mitglieder der Gilde „Qualität & Test", kurz QUEST. Unsere Gilden sind Expertenkreise, die projektübergreifend hinzugezogen werden. Die QUEST-Gilde sorgt nicht nur für Qualitäts- und Testmanagement im Unternehmen, sondern begibt sich auch auf die Suche nach unbekannten Unruhestiftern. Mehr zu unseren Gilden, gibt es hier: Agile Softwareprojekte & Innovation: Gilden bei eXXcellent solutions
Weitere Informationen:
|
Haben Sie Fragen zu diesem Thema? Julia Zwiesler ist Ihre Ansprechpartnerin. Sie freut sich über Ihre Kontaktaufnahme!
Oder informieren Sie sich auf unserer Website über unsere Kompetenzen im Bereich Qualitätssicherung & Testing:
Quellen: Die Protagonisten wurden generiert mit Dall-E / ChatGPT |
Über Roman Klasen

|
Roman Klasen ist Senior Software Engineer bei der eXXcellent solutions gmbh in Darmstadt. Während seiner Promotion in experimenteller Teilchenphysik entwickelte er numerische Algorithmen für Detektorhardware, bevor er 2024 zu eXXcellent solutions wechselte. Als Software Engineer setzt er technisch detailorientiert Kundenwünsche um. Er ist neben der QUEST-Gilde außerdem Mitglied in der AI/ML-Gilde, wo er seine Stärken in der linearen Algebra einbringt. |
Tags: Alle Blogbeiträge, Technologien, Entwicklung & Methodik
