Update 2026:Seit Veröffentlichung dieses Artikels hat sich Generative KI rasant weiterentwickelt. Lokale Modelle wie hier beschrieben sind weiterhin ein Baustein, die skizzierte Lösung (ein einzelner lokaler Assistent) entspricht aber nicht mehr dem heutigen Stand für produktive Szenarien. Mehr dazu, wie Sie Generative KI heute sicher und gewinnbringend einsetzen können:
|
Effizientes und sicheres Coding mit lokalem KI-Assistenten
Seit ChatGPT hält KI zunehmend Einzug in den Arbeitsalltag – sei es, um sich schnell mal eine Begriffsdefinition für die nächste Präsentation ausspucken zu lassen oder ein paar Zeilen Code. Die Qualität hängt dabei nicht nur von der Leistungsfähigkeit der Server, sondern auch von dem Large Language Model (LLM) ab, auf das die KI zugreift. Dabei stellt sich die Frage, ob solche Tools effektiv für die Softwareentwicklung genutzt werden können. Denn Code-Vervollständigungstools wie z.B. GitHub Copilot werden zwar ständig verbessert, bergen aber auch ein Risiko: Unsere Daten landen bei einem externen Dienst, dessen Nutzung wir nicht vollständig kontrollieren können.
Bei der Entwicklung von Individualsoftware geht es immer auch um firmenspezifische Interna. Kunden kommen zu uns, weil gängige Lösungen ihre speziellen Anforderungen nicht erfüllen können. Speziallösungen, die Wettbewerbsvorteile sichern, erfordern in der Regel eine hohe Vertraulichkeit. Neben der Qualität spielt auch die Effizienz eine wichtige Rolle in unseren Projekten. Nicht zuletzt deshalb, haben wir GitHub Copilot bereits getestet und unsere Erfahrungen in der ersten Ausgabe der JavaSPEKTRUM 2024 veröffentlicht. Nach unseren positiven Erfahrungen lag es für uns auf der Hand: Wir brauchen eine Alternative, die vergleichbare Ergebnisse liefert und uns gleichzeitig einen angemessenen Datenschutz ermöglicht.
Wie können wir also die Effizienz von Tools wie GitHub Copilot nutzen und gleichzeitig den Qualitäts- und Vertraulichkeitsanforderungen gerecht werden?
Indem wir einen KI-Assistenten selbst hosten.
Mit einem lokal gehosteten KI-Assistenten behalten wir nicht nur die Kontrolle über die Daten, die wir verarbeiten, sondern können KI auch in unserem Projektalltag effektiv nutzen. Das Beste daran: Auch die Umsetzung ist effizient, denn mit der richtigen Kombination bereits existierender Tools, muss das Rad nicht neu erfunden werden. Wir zeigen, wie’s geht.
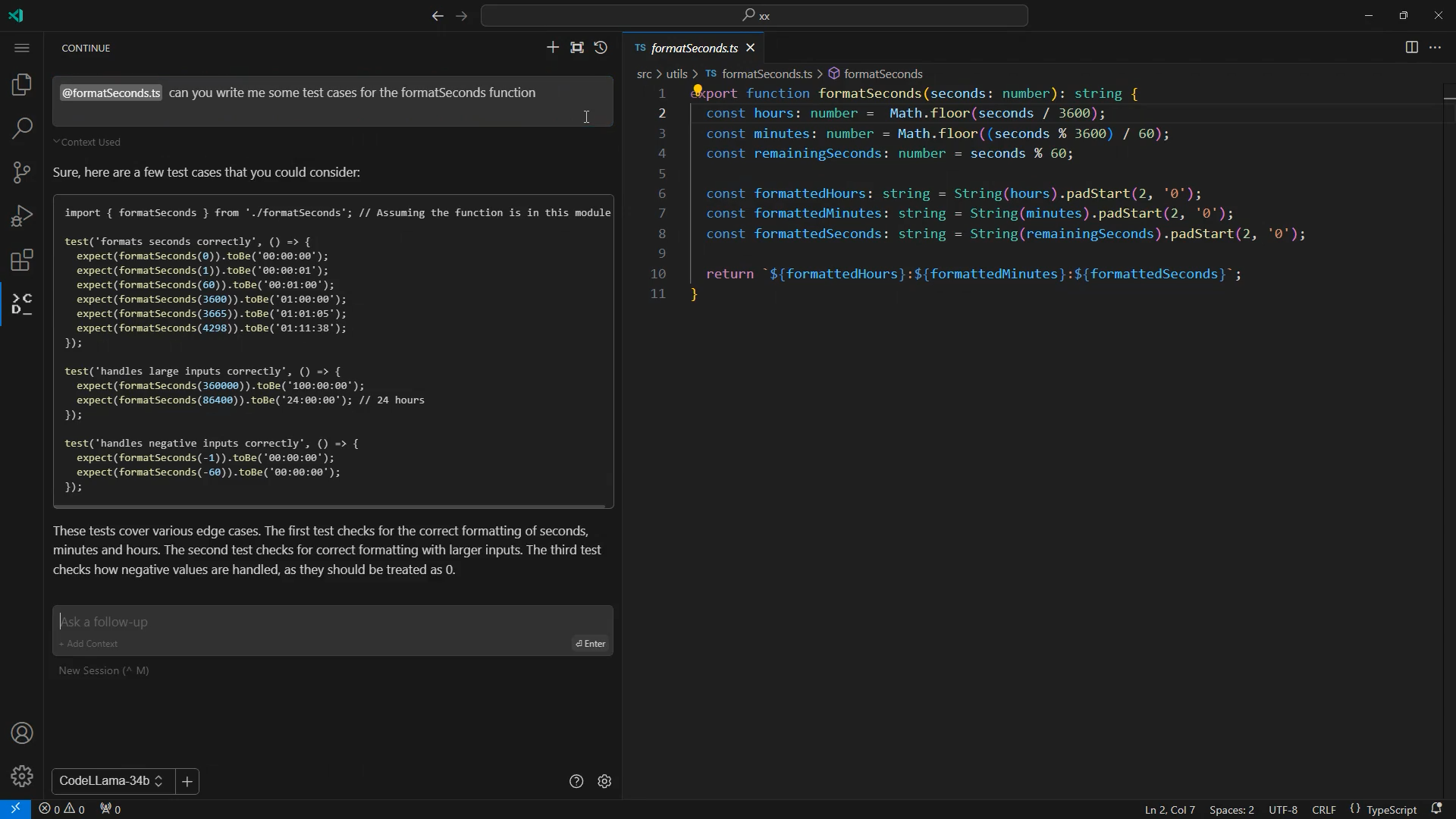 Code-Vorschlag generiert durch Code Llama, Ansicht mit der Editor Extension Continue (© eXXcellent solutions)
Code-Vorschlag generiert durch Code Llama, Ansicht mit der Editor Extension Continue (© eXXcellent solutions)
Schritt 1: Large Language Model auswählen
Um unsere Qualitätsanforderungen zu erfüllen, benötigen wir ein starkes Large Language Model (LLM), welches auf Programmieraufgaben spezialisiert ist. Derzeit gibt es zahlreiche Open Source LLMs, zu den beliebtesten zählt aufgrund der Leistung jedoch Code Llama von Meta.
Code Llama ist ein LLM, das auf dem Sprachmodell Llama 2 basiert und mit speziellen Code-Datensätzen trainiert wurde. Es kann Code und natürliche Sprache durch Code erzeugen, und eignet sich daher wie GitHub Copilot für Code-Vorschläge, Code-Generierung, Code-Erläuterung und zur Unterstützung beim Schreiben von Code-Dokumentationen. Code Llama sowie Llama 2 wurden von Meta entwickelt und sind frei für die kommerzielle Nutzung. Dies ist der KI-Strategie von Meta zu verdanken:
The generative AI space is evolving rapidly, and we believe an open approach to today’s AI is the best one for developing new AI tools that are innovative, safe, and responsible. – Meta1
Das Code Llama-Modell wird als Grundlage für viele andere LLMs für Coding Tasks verwendet, da Meta nicht nur das Sprachmodell, sondern auch die für das Training verwendeten Parameter zugänglich gemacht hat. Dies ermöglicht es, das Modell weiter zu trainieren und bei Bedarf an die eigenen Bedürfnisse anzupassen.
Code Llama ist in vier verschiedenen Größen erhältlich (7B, 13B, 34B und 70B), die jeweils die Anzahl der Parameter darstellen. Mit einfachen Worten: Je größer das Modell ist, desto leistungsfähiger ist es. Bei der Wahl der Größe muss auch die Rechenkapazität des Systems berücksichtigt werden. Je nach Anforderung kann daher auch ein kleineres Modell sinnvoll sein.
Schritt 2: Launch mit Ollama – "Run LLM, run."
Der erste Schritt ist getan, doch wie lässt sich das LLM ohne viel Aufwand zum Laufen bringen? Für jedes LLM gibt es Anforderungen und Anweisungen, um es auszuführen. Neben dem Modell selbst, muss man in der Regel einige Abhängigkeiten installieren und Skripte konfigurieren, um es nutzen zu können. Doch auch hier gibt es ein praktisches Tool: Mit Ollama lassen sich LLMs in wenigen Schritten lokal ausführen und verwalten.
Darüber hinaus fungiert Ollama als Vermittler zwischen dem Benutzer und dem Modell, über eine CLI oder REST API Schnittstelle. Aufgrund der Einfachheit erfreut sich Ollama als Open-Source-Projekt zunehmender Beliebtheit und erfährt jede Woche mehr und mehr interessante Verbesserungen. Mit Code Llama und Ollama haben wir somit einen vielversprechenden Grundstein für unseren Code-Vervollständigungs-Assistenten gelegt. Chatten mit Code Llama via der CLI von Ollama ist bereits möglich, doch unser Höhenflug alla GitHub Copilot steht noch aus…
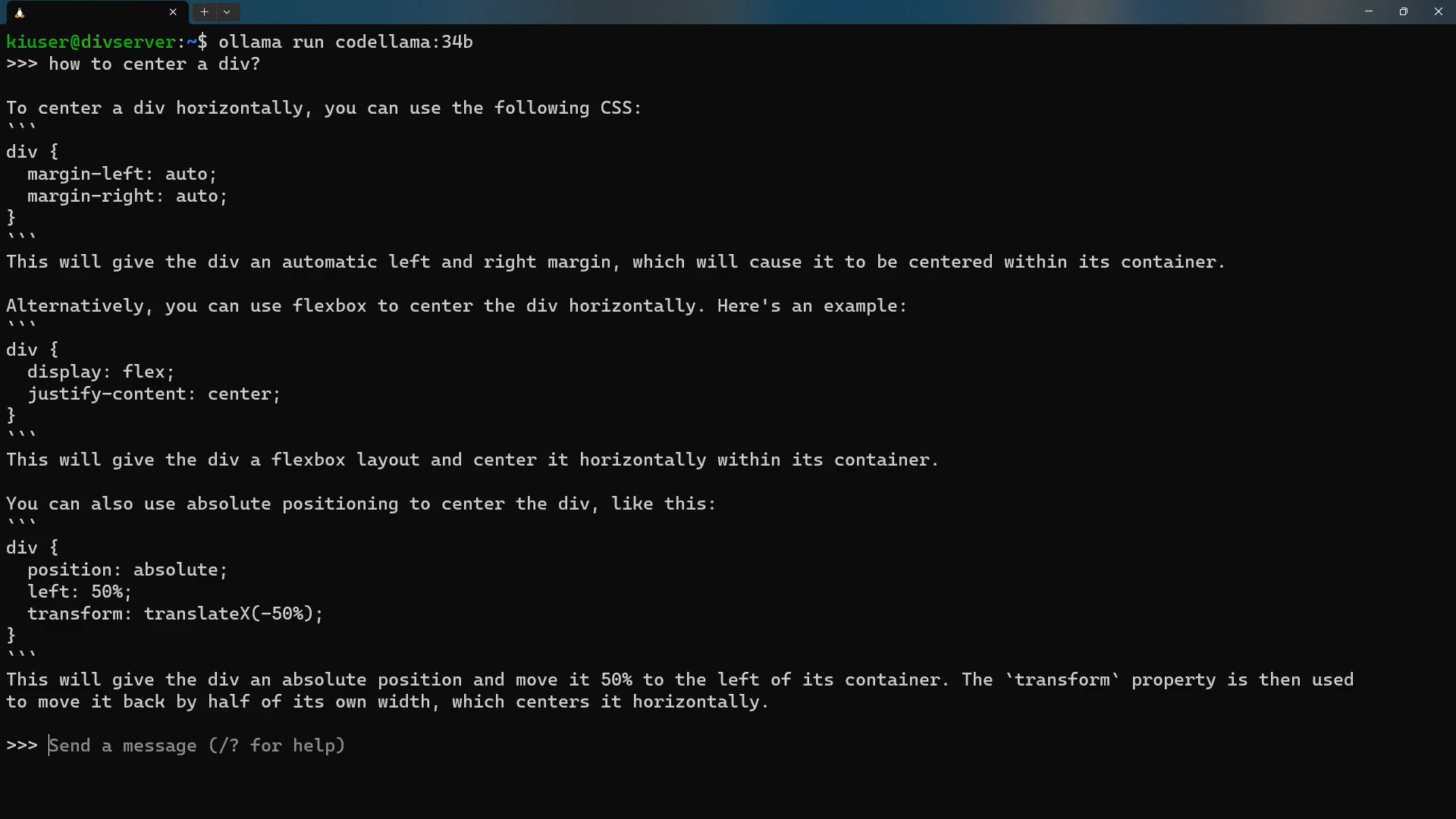 Chatten mit Code Llama via Ollama CLI (© eXXcellent solutions)
Chatten mit Code Llama via Ollama CLI (© eXXcellent solutions)
Schritt 3: Nutzung mit Continue
Wir können bereits Prompts ins Eingabefeld schreiben und Antworten erhalten, aber die Interaktion mit einer CLI bietet nicht die ideale Benutzererfahrung. Unser Ziel ist es, direkt über unseren Code- Editor mit dem LLM zu interagieren. Hierfür eignet sich z.B. Continue.
Continue ist eine Editor Extension, die die Interaktion mit einem LLM aus dem Editor heraus erleichtern kann, indem eine Reihe von vorkonfigurierten Befehlen verwendet wird, die im Hintergrund an vorkonfigurierte Template-Prompts angepasst werden.
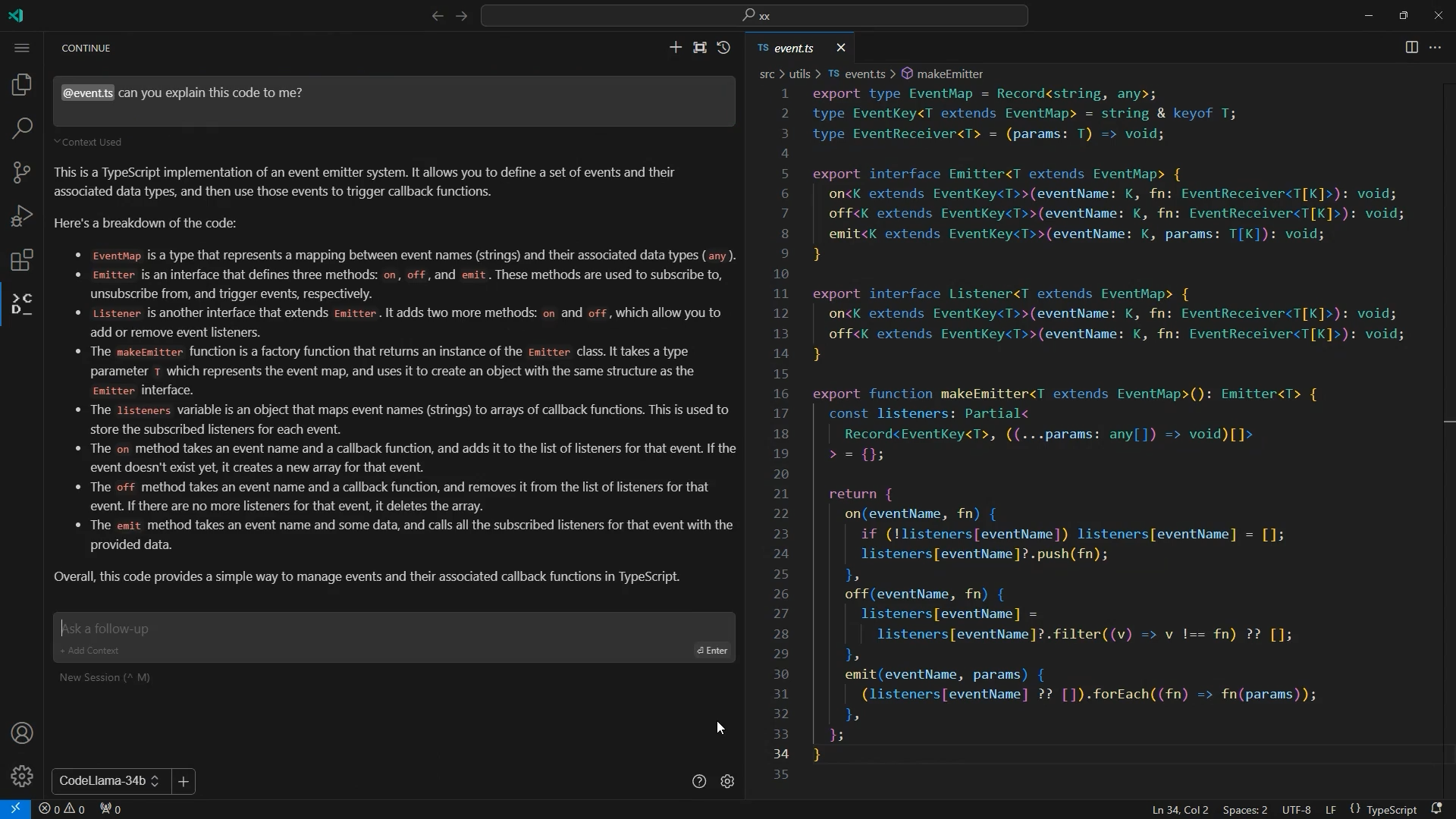 Code-Erläuterung mit Code Llama und Continue (© eXXcellent solutions)
Code-Erläuterung mit Code Llama und Continue (© eXXcellent solutions)
Nachdem wir die Continue Extension zu unserem Editor hinzugefügt und die Einstellungen zur Verwendung von Code Llama durch Ollama konfiguriert haben, können wir LLMs in unserem täglichen Coding verwenden. Da Ollama uns erlaubt, mit mehr als einem Modell zu kommunizieren, können wir in Continue verschiedene LLMs konfigurieren und das am besten geeignete für eine bestimmte Aufgabe auswählen.
Gesteigerte Effizienz und Qualität
Mit Generative AI lässt sich Programm-Code in Sekundenschnelle produzieren. Durch die Möglichkeit des Trainings des verwendeten Large Language Models, kann die Leistung eines solchen KI-Assistenten an die Anforderungen angepasst und die Qualität verbessert werden. Mit dem entsprechenden LLM ist es nicht nur möglich Code schreiben zu lassen. Durch die Fähigkeit von Code Llama natürliche Sprache auszugeben, lassen sich Lösungen erläutern oder bereits geschriebener Code auf Fehler überprüfen. Lösungen können so leichtgewichtig getestet und Fehler frühzeitig erkannt werden. Dies bedeutet für die Projektarbeit nicht nur eine Steigerung der Qualität, sondern auch eine erhebliche Beschleunigung und damit Kosteneinsparung für unsere Kunden.
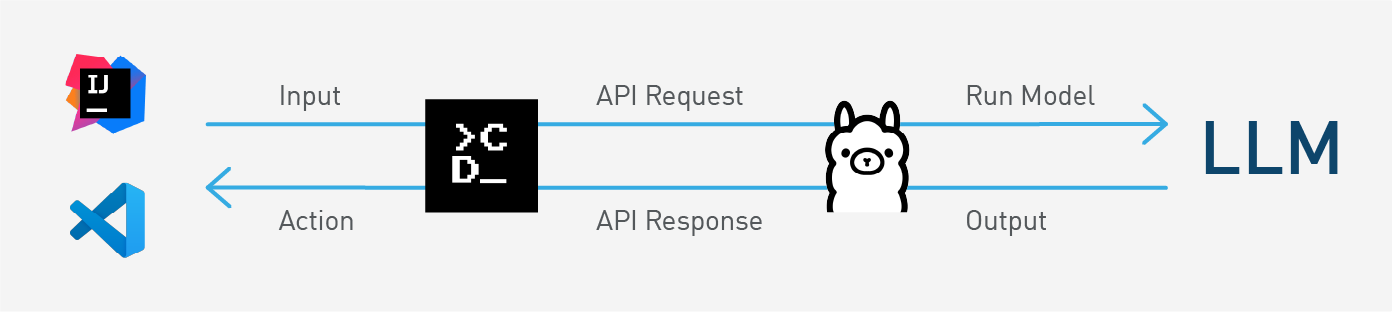
Beispiel-Elemente für lokalen KI-Assistenten: Editor ( IntelliJ IDEA2 o. Visual Studio), Continue, Ollama, LLM. (© eXXcellent solutions)
Mit der Kombination aus Code Llama als LLM, Ollama als Verwaltungstool und Continue als Editor Extension, haben wir einen effizienten, lokalen und kostengünstigen Code-Assistenten, der über ähnliche Eigenschaften wie GitHub Copilot verfügt. Was die Leistungsfähigkeit betrifft, ist eine solche Kombination zwar nicht mit dem Vorbild gleichzusetzen, bietet jedoch einen leichtgewichtigen Zugang zu Generative AI mit dem großen Vorteil des Datenschutzes. Mit dem richtigen Umgang im Sinne einer „Augmented Intelligence“ lassen sich solche Lösungen effektiv und gewinnbringend im Projektalltag einsetzen. Durch den modularen Aufbau können auch andere Bausteine verwendet werden, je nach Anforderung oder Präferenz.
KI-Assistenten helfen nicht nur uns, unsere Arbeit effizienter zu gestalten und unseren Kunden eine schnellere, kostengünstigere und qualitativ hochwertige Projektabwicklung zu ermöglichen. Auch in den von uns entwickelten Anwendungen für unsere Kunden lassen sich solche Assistenten integrieren und an den jeweiligen Bedürfnissen und Zwecken ausrichten.
Weitere Informationen:
|
Sie haben Fragen zum Thema? Schreiben Sie uns gerne eine E-Mail. Unser Prokurist und Projektmanager Gregor Hermann Ist Ihr Ansprechpartner!
Oder informieren Sie sich über unsere Lösungen & Kompetenzen auf unserer Webseite:
Quellen: 1 https://ai.meta.com/blog/code-llama-large-language-model-coding/ |
Über Alex Muñoz

|
Alex Muñoz ist Senior Software Engineer bei der eXXcellent solutions gmbh in Ulm. Sein Schwerpunkt liegt in der Frontend-Entwicklung sowie modernen Webtechnologien. Seine Begeisterung für Künstliche Intelligenz bringt er in Projekte mit ein und baut als Mitglied der Gilde AI | ML | Data Science sein Wissen kontinuierlich aus. |
Tags: Alle Blogbeiträge, Technologien, KI & Analytics, Wissen & Weiterbildung
